5 Most Common LLM Parameter-Efficient Fine-Tuning (PEFT) Techniques Explained:LoRA, LoRA-FA, VeRA, Delta-LoRA, LoRA+
In the Era of Large Models
In the era of large models, full parameter fine-tuning (Full Fine-tuning) of LLMs is often impractical. Taking a hundred-billion-parameter model as an example, complete fine-tuning requires:
- Hundreds of GB of VRAM/Memory
- Extremely costly compute clusters
- Long training cycles
To solve these problems, the industry has proposed PEFT (Parameter-Efficient Fine-Tuning) — achieving near full-parameter fine-tuning performance by training only a small fraction of the model's parameters.
The core idea of PEFT typically revolves around:
Finding a "low-rank representation" for weight matrices in the model, thereby enabling effective learning with minimal additional parameters.
This article will introduce the 5 most mainstream PEFT techniques with a clear structure, helping readers understand their approaches and differences from a systematic perspective.
Background: Why is Low-Rank Approximation So Important for LLM Fine-Tuning?
Each Transformer layer contains numerous matrix multiplications, such as:
- Attention's Q/K/V projection matrices
- Linear transformations in FFN layers
These weight matrices are enormous in scale (e.g., 4096×4096), making direct training prohibitively expensive.
Low-rank decomposition tells us:
Effective information in large matrices can often be represented through low-dimensional subspaces.
Therefore, the core approach of many PEFT methods is:
- Don't directly modify the original weight matrix W
- Instead, add lightweight low-rank matrices A and B
- Or design trainable structures with smaller dimensions
Top 5 LLM Fine-Tuning Techniques Explained
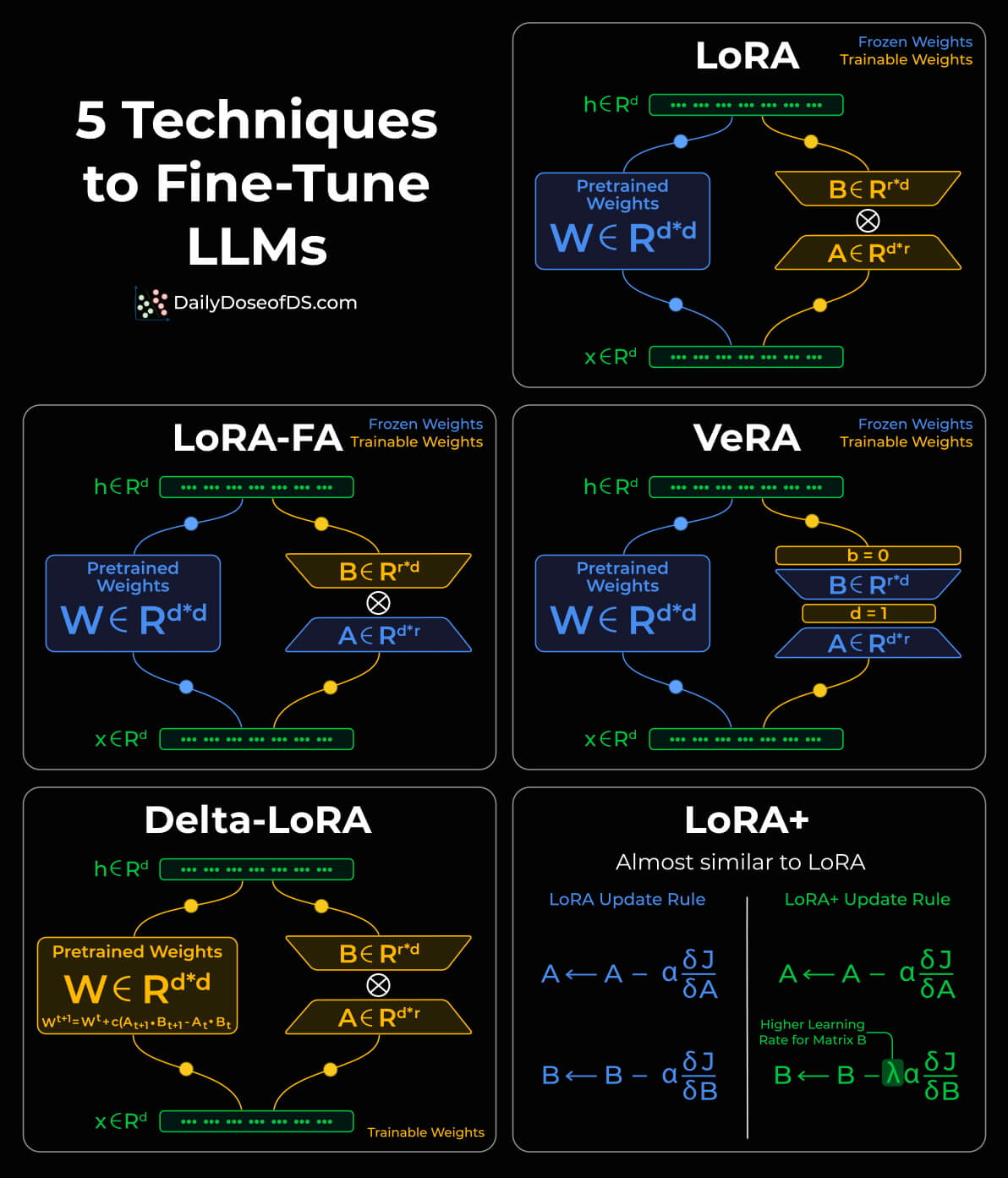
1) LoRA: The Most Classic and Widely Adopted PEFT Technique
Core Idea:
Introduce two small matrices A (dimensionality reduction) and B (dimensionality expansion) alongside the original weight matrix W.
During training:
- W remains frozen
- Only A and B are trained
- Update form:
ΔW = B × A
Characteristics:
- Extremely few additional parameters (rank typically 4~64)
- Memory-friendly
- Performance close to full-parameter fine-tuning
LoRA has become the standard PEFT technique, with almost all frameworks (such as HuggingFace PEFT, LLaMA-Factory) supporting it by default.
2) LoRA-FA: Reducing Activation Memory Consumption
The LoRA training process requires:
- Preserving gradients of A and B
- Preserving intermediate activation values
This consumes considerable VRAM.
LoRA-FA's Improvement:
- Freeze matrix A
- Train only matrix B
This can significantly reduce:
- Activation cache
- Intermediate gradients in backpropagation
Advantages:
- More memory-efficient (suitable for 13B / 70B model fine-tuning)
- Smaller parameter scale
Application Scenarios:
- Limited VRAM
- Need for higher batch sizes
3) VeRA: Further Reducing Parameters & Increasing Sharing
In LoRA, A and B are different for each layer.
VeRA's proposed improvement:
- A and B are no longer trainable matrices
- Instead, they are fixed random matrices
- And all layers share the same A and B
The model no longer learns A and B, but instead learns:
- Per-layer scalar vectors b (input scaling) and d (output scaling)
This reduces parameters to the extreme.
Characteristics:
- Extremely low parameter count
- Fast fine-tuning speed
- Suitable for multi-task scenarios (shared structure)
4) Delta-LoRA: Merging Incremental Information Directly into Weights
Traditional LoRA:
- The final ΔW comes from B×A
Delta-LoRA's Approach:
- Observe changes in low-rank updates during training
- Accumulate the difference (delta) between consecutive timesteps A×B into the original W
Form similar to:
W ← W + [(B×A)_{t} − (B×A)_{t−1}]Characteristics:
- W is updated progressively, but without traditional full-parameter training
- Still maintains the advantages of low-rank structure
Applicable Scenarios:
- Need to store more incremental information in weight matrices
- Prefer not to rely on LoRA adapters during inference
5) LoRA+: Simple Upgrade by Optimizing Learning Rate Strategy
In LoRA:
- A and B share the same learning rate
Research has found:
- Increasing the learning rate for B
- Keeping the learning rate for A unchanged
Enables:
- More stable training
- Faster convergence
- Better performance
Essentially a more optimal learning rate scheduling strategy without additional structure.
Advantages:
- Simple to implement
- No additional VRAM overhead
- Stable performance improvement
Technical Comparison Summary
| Technique | Train A | Train B | Train W | Parameters | VRAM | Scenario |
|---|---|---|---|---|---|---|
| LoRA | ✔️ | ✔️ | ❌ | Small | Medium | Standard fine-tuning |
| LoRA-FA | ❌ | ✔️ | ❌ | Smaller | Lower | Limited VRAM |
| VeRA | ❌(Random) | ❌(Random) | ❌ | Minimal | Minimal | Multi-task/Extreme compression |
| Delta-LoRA | ✔️ | ✔️ | ✔️(Incremental) | Medium | Medium | Update to base weights |
| LoRA+ | ✔️ | ✔️(Higher LR) | ❌ | Small | Medium | Faster convergence |
Conclusion
As model scales continue to grow, PEFT will remain a core method for LLM fine-tuning long-term. LoRA and its derivative techniques each have their merits:
- LoRA is the standard solution
- LoRA-FA focuses on VRAM optimization
- VeRA pursues minimal parameter sharing
- Delta-LoRA provides a new path for weight updates
- LoRA+ improves performance through learning rate strategy
Understanding the differences between these methods helps make the most suitable choices in engineering practice, such as:
- Inference efficiency and deployment constraints
- Target task scale
- Available compute resources